Leonardo M. Bastos
Assistant Professor
Integrative Precision Agriculture

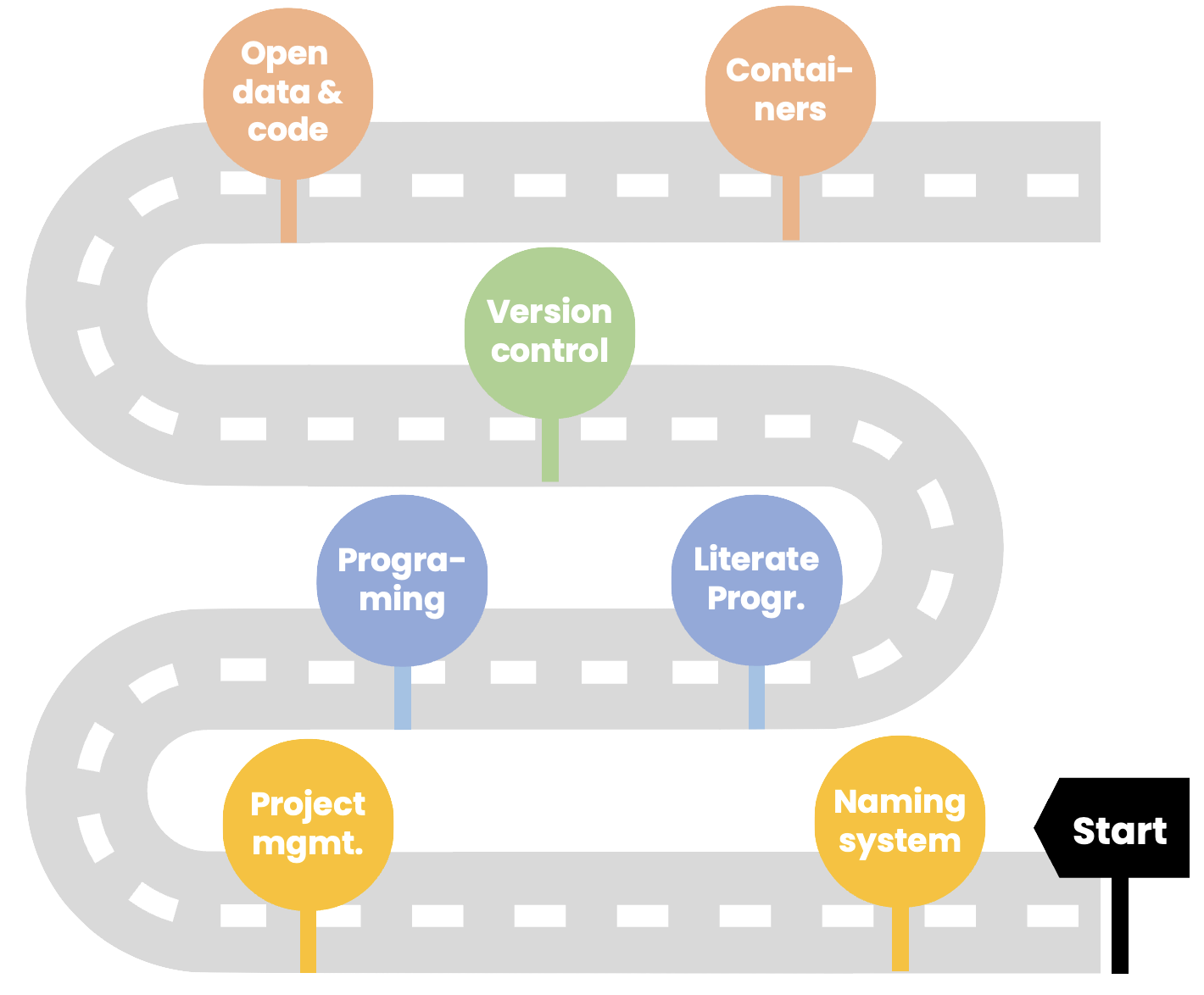
Starting my M.Sc., this is how my file management system looked like:

- Data, code, figures all mixed in same folder
- File names not very informative
- And this was just my first year! 😱
- Looks familiar?
Principles of project management
From this: 
To this:

Principles of project management
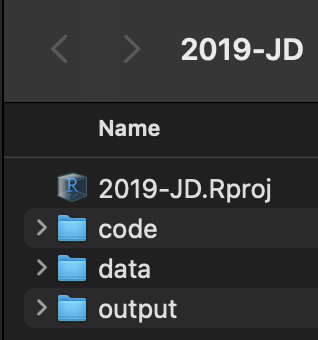
- Create a minimum of three sub-folders: data, code, output
Principles of project management
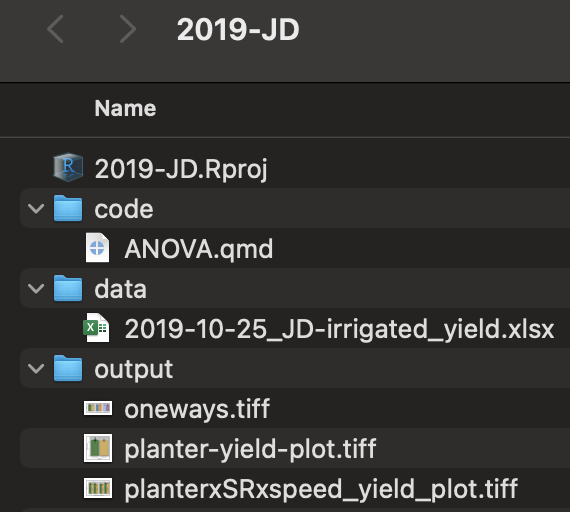
- Create a minimum of three sub-folders: data, code, output
Keep data files in
data, script files incode, and tables and figures inoutputIn RStudio, use RStudio Projects!
Static scripts with .txt or .R

Improvement: using an IDE
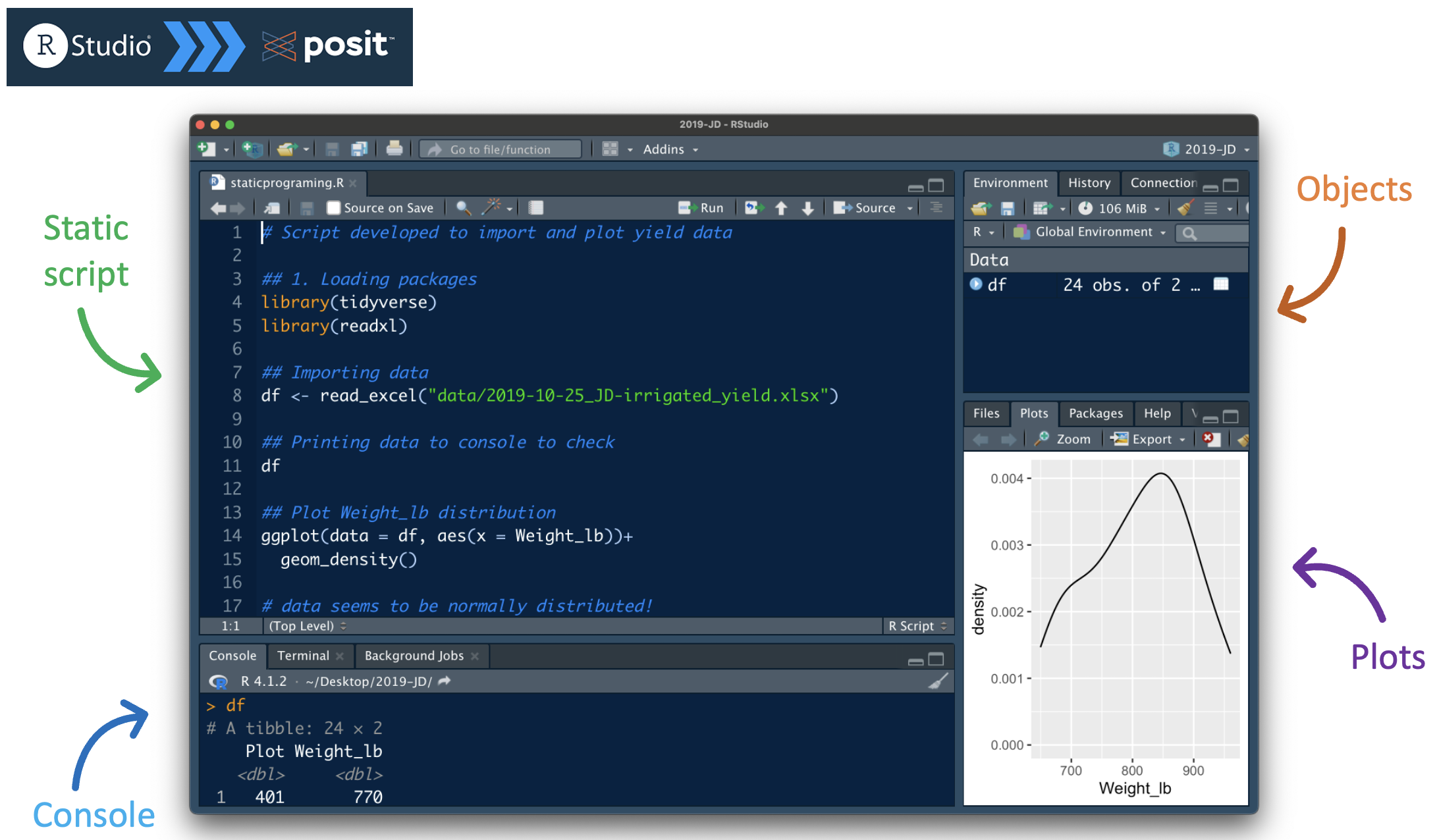
Literate progamming
Mixes code, output, and narrative on the same file
Examples:
![]()

Welcome in, version control
Think of “track changes”, but on any file type
Especially useful for script files (.Rmd, .qmd)
As your code grows and develops, snapshots are saved allowing you to retrieve different versions
This connects your current-self with your past-self (what were I thinking when I decided on doing this step?)
Locally (in your own machine), use
![]()

Welcome in, GitHub
GitHub is an online centralized platform that combines git, collaborative tools, and cloud storage, all free 💸
You can choose if your projects hosted on GitHub (i.e., a repository) can be seen by everyone (public) or only by you and invited collaborators (private)

Containerizing projects
- To avoid discrepancies of software versions, we can use containers
- Containers keep track of all software versions in a project, and ship that project with those default versions
- This ensures the project is reproducible not only for collaborators, but also your future self
- One example of container software is
![]()

Personal marketing
This entire presentation was made with quarto, and its source code is available on my GitHub
You can find more info on my lab’s website (also made with quarto): Bastos Lab
![]()
You can find my data science teaching material on my blog: agRonomy
Wish to learn and apply these concepts to your own research?
Applications of data science in ag research, Spring 2024
Thanks! 🙏 💻
